Lv. 1 머신러닝 기초 - EDA
머신러닝 이란?
- 컴퓨터가 학습을 할 수 있도록 하는 연구분야
- 인공지능을 소프트웨어적으로 구현하는 머신러닝은 컴퓨터가 데이터를 학습하고 스스로 패턴을 찾아내 적절한 작업을 수행하도록 학습하는 알고리즘
- 머신러닝 시스템(ML)은 관측데이터 D로부터 성능지수P를 최적화 하는 모델M을 자동으로 만드는 기술
- 환경(Environment)과의 상호작용을 통해서 축적되는 경험적인 데이터(Data)를 바탕으로 지식, 즉 모델(Model)을 자동으로 구축하고 성능(Performance)룰 향상하는 시스템
EDA
- Exploratory Data Analysis
- 데이터를 분석하고 결과를 내는 과정에 있어서 지속적으로 해당 데이터에 대한 ‘탐색과 이해’를 기본으로 가져야 한다는 것
- 수집한 데이터가 들어왔을 때, 이를 다양한 각도에서 관찰하고 이해하는 과정
- 데이터를 분석하기 전에 그래프다 통계적인 방법으로 지료를 직관적으로 바라보는 과정
1. import ; 라이브러리 불러오기¶
데이터 분석 도구, 즉 라이브러리를 불러오는 것 부터가 데이터 분석의 시작이다.
라이브러리란,
주로 소프트웨어를 개발할 때 컴퓨터 프로그램이 사용하는 비휘발성 자원의 모임
소프트웨어 개발 시 사용되는 프로그램의 구성요소로, 공통으로 사용될 수 있는 특정 기능들을 모듈화 한 것이다.
import [라이브러리] as [사용할 이름]
#관례적으로 pandas는 pd, numpy는 np로 alias를 지정
2. read ; 데이터 불러오기¶
파이썬에서 데이터 파일(csv파일)을 불러오기 위해서는 pandas라이브러리를 이용한다. 해당 라이브러리에 read_csv함수로 csv파일을 불러온다.
import pandas as pd
data=pd.read_csv('파일경로/파일이름.csv')
3. shape ; 행 열 갯수 관찰하기¶
read_csv()를 통해 csv 파일을 pandas라이브러리에서 제공하는 DataFrame객체로 변환했다면, shape attribute로 불러온 데이터의 행과 열의 갯수를 관찰할 수 있다.
[DataFrame변수명].shape
4. head ; 데이터 확인하기¶
head()메서드는 데이터 전부를 보여주지 않고 데이터의 상단부분만 출력하여 보여준다. head와 유사한 tail()메서드는 데이터의 하단 부분을 출력하여 보여준다
imoprt pandas ad pd
train.pd.read_csv('data/train.csv')
train.head()
#parameter지정하지 않으면, train데이터의 상단 5개 행 출력
5. is_null : 결측치 확인하기¶
결측치 = mission value 로 데이터에 값이 없는 것을 뜻한다.
pandas에서는 결측치를 NaN 값으로 표현한다.
isnull()메서드를 통해 NaN값을 확인 할 수 있으며, True/Fales값을 리턴한다.
import pandas as pd
import numpy as np
df = pd.DataFrame({
'name': ['kwon', 'park', 'kim'],
'age':[30, np.nan, 19],
'class':[np.nan, np.nan, 1]
})
df.isnull()
isnull() 메소드 뒤에 sum() 메소드를 추가해주면, DataFrame의 각 열별 결측치의 수를 확인할 수 있다.
df.isnull().sum()
Lv1. 머신러닝 기초 - 전처리
전처리(Data Preprocessing)
우수한 예측 분석결과는 잘 정돈된 데이터에서 출발한다.
즉, 정교한 예측 분석 모델을 얻기 위해서는 수집된 데이터의 누락된 부분, 오차 혹은 데이터 처리에 있어서 가공할 부분은 없는지 살펴보아야한다.
데이터 전처리 종류
- 데이터 클리닝
- 데이터 통합
- 데이터 변환
- 데이터 축소
- 데이터 이산화
데이터의 결측치 및 이상치를 확인하거나 제거하고 불일치되는 부분을 일관성 있는 데이터의 형태로 전화하는 등의 과정을 데이터 전처리라고 한다.
1. info ; 데이터 기본 정보 확인하기¶
DataFrame에 info()메소드를 사용하면, 피쳐들의 기본정보(결측치와 데이터 타입 등)를 확인할 수 있다.
모델링에 앞서 결측치가 있다면, 결측치들을 어떻게 다뤄야 할 지 고민하고 처리하는 과정이 필요하다.
import pandas as pd
import numpy as np
df = pd.DataFrame({
'name': ['kwon', 'park', 'kim'],
'age':[30, np.nan, 19],
'class':[np.nan, np.nan, 1]
})
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 name 3 non-null object
1 age 2 non-null float64
2 class 1 non-null float64
dtypes: float64(2), object(1)
memory usage: 200.0+ bytes
2. dropna, fillna ; 결측치 삭제, 대체¶
dropna()를 사용하면, 결측치를 갖는 행을 DataFrame객체에서 삭제한다.
fillna()를 사용해 모든 결측치를 인자 값으로 대체할 수도 있다.
df.dropna()
| name | age | class | |
|---|---|---|---|
| 2 | kim | 19.0 | 1.0 |
df.fillna(100)
| name | age | class | |
|---|---|---|---|
| 0 | kwon | 30.0 | 100.0 |
| 1 | park | 100.0 | 100.0 |
| 2 | kim | 19.0 | 1.0 |
Lv1. 머신러닝 기초 - 모델링
Model
머신 러닝 모델은 특정 유형의 패턴을 인식하도록 학습된 파일이다.
데이터 세트에 대해 모델을 학습하여 해당 데이터로 추론하고 학습하는 데 사용할 수 있는 알고리즘을 제공한다.
algorithms Vs. models
- algorithms
- 코드로 구현되고 데이터에서 실행되는 절차를 가진다.
- 머신러닝 모델의 자동 프로그래밍 유형들을 제공
- models
- 알고리즘에 의해 출력되며 모델 데이터와 예측 알고리즘으로 구성
data modeling
- 사용가능한 데이터를 기반으로 논리적 의사 결정을 모방하는 머신 러닝 알고리즘의 생성, 학습 및 배포의 의사 결정 프로세스
- 실시간 분석, 예측 분석, 증강 분석과 같은 고급 인텔리전스 방법론을 지원
1. Scikit-learn(DecisionTreeClassifier)¶
python 대표 머신러닝 라이브러리로 간단하고 효과적으로 데이터를 분석하며 기계 학습을 시험해 볼 수 있다.
scikit-learn 사용 전 numpy, pandas, scipy 라이브러리에 설치가 먼저 수행되어야 한다.
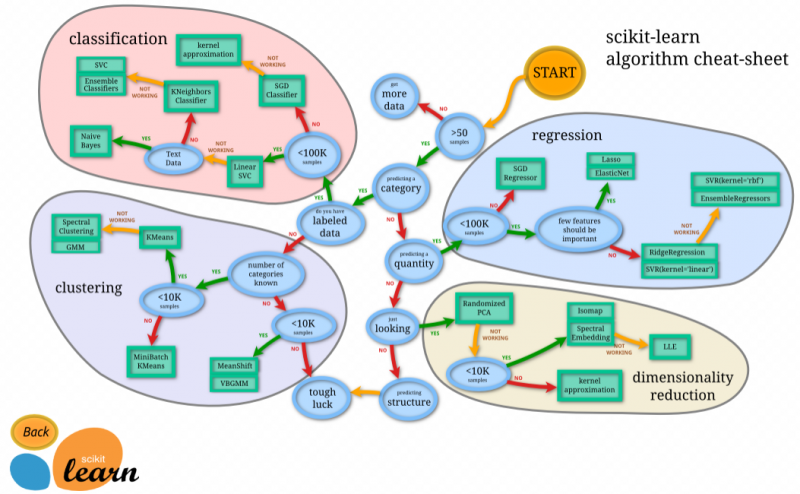
주요기능
- 분류(Classification)
Identifying which category an object belongs to.
주어진 데이터가 어느 클래스에 속하는지 판별하는 것, 정답 O- SGD(stochastic gradient descent) - 대규모 데이터(10만건 이상)의 경우 추천, 선형의 클래스 분류 방법
- 커넬근사 - SGD로 잘 분류할 수 없는 경우에 이용, 비선형적인 클래스 분류 방법으로 역시 대규모 데이터에 적합
- Linear SVC - 중소규모(10만건 미만)의 경우 추천, 선형의 클래스 분류 방법
- k근접법 - Linear SVC로 잘 분류되지 않는 경우 사용, 비선형적 클래스 분류 방법으로 중소규모의 데이터 분류에 추천
- 회귀(Regression)
Predicting a continuous-valued attribute associated with an object.
전달된 데이터를 바당으로 값을 예상, 정답 O- SGD(stochastic gradient descent) - 대규모 데이터의 경우 추천, 선형의 회귀 분류 방법
- LASSO / ElasticNet - 중소규모로 설명변수(원인이 되고 있는 변수)의 일부가 중요한 경우에 추천하는 회귀 분석 방법
- Ridge / Linear SVC - 중소규모로 설명변수의 전부가 중요한 경우에 추천하는 회귀 분석 방법
- SVR(가우스 커넬), Ensembloe - Ridge / Linear SVC로 잘 분석되지 않는 경우에 이용하며, 비선형적 회귀 분석 방법
- 클러스터링(clustering)
Automatic grouping of similar objects into sets.
전달된 데이터를 어떤 규칙에 따라 나누는 것, 정답 X- KMeans - 몇 개의 클러스터를 분할할지, 사전에 정해둔 경우에 추천하는 클러스터링 분석 방법
대규모 데이터의 경우, miniBatch로 데이터를 나누면서 학습하는 방법을 취함 - 스펙트럼 클러스터링(GMM) - KMeans로 잘 분석되지 않는 경우에 이용하며, 비선형적인 클러스터링 분석 방법
- MeanShift / VBGMM - 몇 개의 클러스터로 나눌지 사전에 정할 수 없는 경우에 추천하는 클러스터링 분석 방법
- KMeans - 몇 개의 클러스터를 분할할지, 사전에 정해둔 경우에 추천하는 클러스터링 분석 방법
- 그 외 기타 기능
- 차원감소 - 전달된 데이터의 차원 수가 많은 경우, 학습효율이 떨어지므로 차원을 감소시키는 전처리를 실시
PCA, 커넬PCA, Isomap, SpectralEmbedding 등 - 하이퍼 파라미터의 최적화 - 기계학습을 실행할 때, 학습 방법등을 조정하는 수치를 하이퍼 파라미터라 칭함.
그리드 서치, 크로스밸리테이션 등
- 차원감소 - 전달된 데이터의 차원 수가 많은 경우, 학습효율이 떨어지므로 차원을 감소시키는 전처리를 실시
사용방법
- 라이브러리 임포트
- 학습 데이터나 테스트 데이터 준비
- 알고리즘 지정과 학습 실행
- 테스트 데이터로 테스트
- 필요에 따라 정밀도 등, 시각화
2. 의사결정나무_모델개념¶
결정 트리는 의사 결정 규칙과 그 결과들을 트리구조로 도식화한 의사 결정 지원 도구의 일종

각 행들은 feature를 갖고, 해당 feature에 대해 특정한 하나의 값을 정한다면, 이를 기준으로 모든 행들을 두개의 node로 분류, 즉 이진분할 할 수 있다.
대표적인 의사결정나무인 CART 의사결정 나무가 이진분할을 사용한다.
파생된 두 개의 node에서 또 다시 각 node를 feature로 정하고 분류를 진행하는 과정을 반복 -> data들이 분류되며 이것이 의사결정 나무의 원리가 된다.
특정한 값을 정하는 의사결정 나무의 대원칙은 "한쪽 방향으로 쏠리도록"이다.
공평하게, 비슷한 양으로 분류되도록 하는 것이 아닌, 한쪽으로 쏠리도록 구성하여 특정한 값을 찾는 것이며, 이를 불순도로 계산해서 찾아낸다.
import sklearn
#라이브러리 import
from sklearn.tree import DecisionTreeClassifier
#모듈(의사결정나무) import
3. 의사결정나무_모델선언¶
from [라이브러리] import [모듈]
model = 모듈명()
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
4. Fit ; 모델훈련¶
모델 선언 후, fit(X,Y) 함수를 사용하여 모델을 훈련
X 데이터는 예측에 사용되는 변수, Y 데이터는 예측결과 변수
X데이터는 drop함수를 이용해 예측할 feature를 제외
이때, axis = 0 혹은 1 의 옵션을 사용할 수 있다.

X_train = train.drop(['제외할컬럼명'], axis=1)
# axis = 1 옵션을 사용해 해당 칼럼 열을 제외한 DataFrame 객체 생성
Y_train = train['예측할컬럼명']
# 예측할 컬럼 명으로 indexing
model = DecisionTreeRegressor()
model.fit(X_train, Y_train)
5. Predict ; 테스트 예측¶
테스트 데이터를 통해 훈련된 모델로 예측
훈련된 모델에서 predict() 매서드에 예측하고자 하는 data 를 인자로 넣어주게 되면 해당 결과 array 할당 가능[할당할 array] = model.predict(test)
# 실습
# predict() 를 이용해 test data 를 훈련된 모델로 예측한 data 를 생성하고 예측결과 상위 5개를 출력하는 코드를 작성하세요.
pred = model.predict(test)
pred.head()
pred[:5]
6. to_csv ; 제출 파일 생성¶
실습
- submission.csv 파일을 read_csv() 를 이용해 df 클래스로 불러옵니다.
- submission df 파일의 count 피쳐를 예측결과로 할당합니다.
- submission df 파일을 to_csv() 를 이용해 csv 파일로 내보닙니다. 여기서 index 옵션은 False 로 지정해주어야 정답 형식과 맞아 떨어져 헤더 오류가 나지 않습니다.
# 1. submission.csv 파일 df 파일로 불러오기
import pandas as pd
submission = pd.read_csv('/content/data/submission.csv')
# 2. submission df 파일의 count 피쳐에 예측결과 할당하기
train = pd.read_csv('/content/data/train.csv')
test = pd.read_csv('/content/data/test.csv')
# data preprocession - 결측치 전처리
train = train.dropna()
test = test.fillna(0)
# model train
import sklearn
from sklearn.tree import DecisionTreeRegressor
model = DecisionTreeRegressor()
X_train = train.drop(['count'], axis=1)
Y_train = train['count']
model.fit(X_train, Y_train)
# test predict
pred = model.predict(test)
submission['count'] = pred
# 3. 제출파일 생성하기
submission.to_csv('sub.csv', index = False)
출처
- https://dacon.io/competitions/open/235698/talkboard/403458?page=1&dtype=recent
- https://machinelearningmastery.com/difference-between-algorithm-and-model-in-machine-learning/
- https://www.intel.com/content/www/us/en/analytics/data-modeling.html
- https://scikit-learn.org/stable/
- https://engineer-mole.tistory.com/16
'Study > Python' 카테고리의 다른 글
| Python | Dacon Lv2 | RandomForest (0) | 2022.03.16 |
|---|---|
| Python | Dacon Lv1 | Review (0) | 2022.03.15 |
| Python | Dacon 머신러닝 기초 (ipynb to html) (0) | 2022.03.14 |
| Python | 데이터 분석 도구 (0) | 2022.03.14 |
| Setting Up! - Anaconda, Jupyter Notebook (0) | 2022.03.03 |